LLM 开发#
心路历程#
在使用学习 LLM 开发的历程中,在这一周学习的前半段,首先是抱着一个开源教程 ↗。这个课中理论部分的内容占比较多,详细的介绍了Prompt Engineering的内容,包括但不限于提示词工程中输入和输出部分,以及如何对 Prompt 进行优化迭代的部分等等。在宏观层面认识到了提示词工程的一些内容,以及关于LLM的一些基础知识。接着就进入该课程的实战部分,主要是使用 LangChain 这个框架进行开发。在该过程则发现,由于框架 API 更新迭代的迅猛,教程中的示例代码早已经过时,于是此时转向 LangChain 官网进行学习 tutorial。
事实证明,官网学习的初期还是非常合适的,看了很多guide,学会了怎么使用LangChain与大模型进行连接,同时官网中的How-go Guide阅读起来对学习这一整个框架非常有利合适。虽然网上有很多批评 LangChain 官网文档的声音,但我真的觉得看起来真的很不错了。到之后,因为急于求成,在阅读一个比较综合的教程Build a Retrieval Augmented Generation (RAG) App ↗的时候,问题逐渐显现了。各种抽象的概念层出不穷,再加上结合到了 Langchain 生态系统中的 Langsmith,整个教程看的更加是云里雾里。于是我就找到了reddit的 LangChain 社区,看看大家对学习 LangChain 这个框架是什么看法。于是下面的一段话进入我的眼睛:
Asking: Why is everyone suddenly ditching LangChain ?
Answering:
- Docs are a mess
- It abstracts far too much and the abstraction it does is very convoluted.
这时我意识到,我好像连一些基本概念都未完全吃透,所以此时使用openai原生的API或许对我来说是更好的选择。openai提供的原生的python库就能满足我最基础的学习需求了。使用更上层的框架简化开发?那就是后话了。
于是我又又又又,转向了学习openai的方向…
基础概念#
在openai官方提供的CORE CONCEPTION中,包括但不限于有以下的内容:
- Text Prompting
- Structured Output
- Function Callings(Tools)
- Conversion State
- Streaming
接下来我将不会
严格按照上面的核心概念的顺序来进行行文。
TextPrompt Prompting#
这一部分也就是提示词工程中的核心内容,提示词创建有两个共识的原则:
- 清晰、明确、具体的指令
- 给予大模型足够的时间进行思考之后回答问题
简单来说,如果使用原生库进行开发的话,就是需要给大模型提供具体详细的上下文,包括但不限于输入输出的详细格式,通过分隔符进行分割防Prompt注入,给出完成任务的具体步骤,
Few-Shot Prompting通过给出合适的示例对大模型进行预热(能够让大模型更加深刻的理解需求和如何回答)…
“Adding more context helps the model understand you better.”
使用Markdown和XML结构化Prompt#
通过特定的格式结构化Prompt,这增强了Prompt的逻辑性,会更加符合 LLM 的“思维模式“,能够达到出乎意料的效果,结构化示例:
# Identity
You are coding assistant that helps enforce the use of snake case
variables in JavaScript code, and writing code that will run in
Internet Explorer version 6.
# Instructions
* When defining variables, use snake case names (e.g. my_variable)
instead of camel case names (e.g. myVariable).
* To support old browsers, declare variables using the older
"var" keyword.
* Do not give responses with Markdown formatting, just return
the code as requested.
# Examples
<user_query>
How do I declare a string variable for a first name?
</user_query>
<assistant_response>
var first_name = "Anna";
</assistant_response>需要说明的是,在 LLM 的Message中,有着明确的角色分工。通过划分角色,也能够更好的指导 LLM 进行回答。一般角色有:
- system: 系统给予 LLM 的指令,优先级最高
- user: 用户给予指令,优先级次于system
- assistant: LLM 本身给出的message
- tool: LLM 发出的tool msg
Function Callings#
众所周知, 一个模型是通过大量的数据集进行训练出来的,所以模型本身内部的数据并不是实时更新的,可能他当前能够获取的数据就截止在几年之前,再新的数据依靠他自己本身是无法进行获取到的。此时通过利用外部的调用,获取数据,就是一个非常有效的方法。Function Callings应运而生,但是其实我更加愿意叫他Tool Calling。 LLM 可以通过“调用”Tool,来获取到外部的最新的其他的信息(或者是其他用户想要让其获取的内容)。前文的“调用”为什么打上引号,因为 LLM 本身是不会对该Tool进行调用的,整体流程如下图:
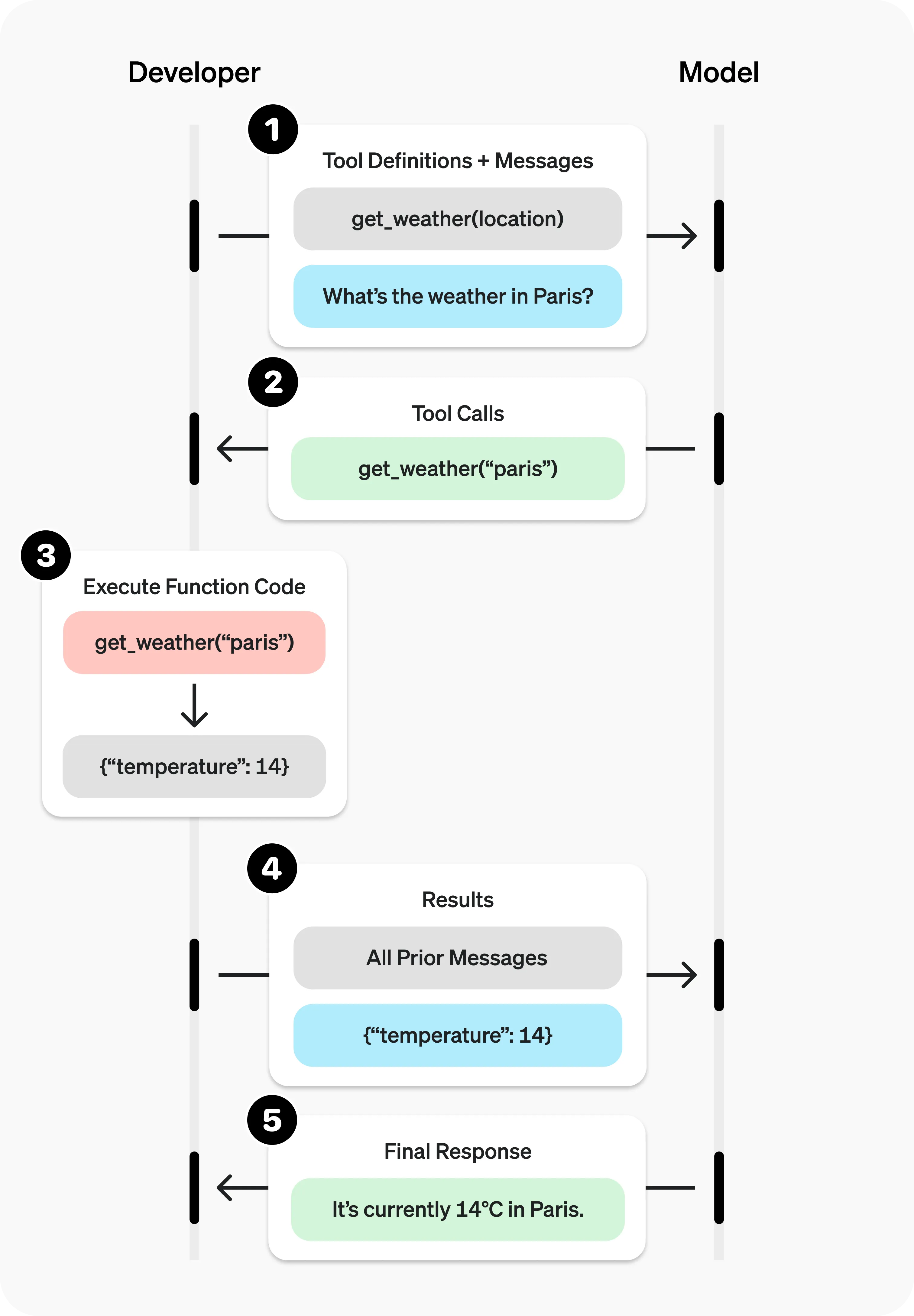
在图中我们可以看到,开发者端通过将Tool的详细定义(包括参数类型、返回类型)以及问题本身交给 LLM , LLM 此时返回一个不同于之前的自然语言的回答,而是返回一个Tool Calls详细信息:
[{
"id": "call_12345xyz",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"latitude\":48.8566,\"longitude\":2.3522}"
}
}]可以看到, LLM 通过分析问题,以及综合Tool Definition,将Tool Calling所需要的所有参数进行返回,在该示例中返回的是对应的城市的经纬度。developer接收到该message,将参数传入与定义好的tool中进行调用:
# 由开发者定义,通过调用外部api返回 LLM 需要的信息
def get_weather(latitude, longitude):
response = requests.get(f"https://api.open-meteo.com/v1/forecast?latitude={latitude}&longitude={longitude}¤t=temperature_2m,wind_speed_10m&hourly=temperature_2m,relative_humidity_2m,wind_speed_10m")
data = response.json()
return data['current']['temperature_2m'] 至此,将查询到的实际温度返回 LLM , LLM 给出最终的Final Response。整个Tool Calling流程中,给 LLM 的tools定义如下:
# 定义tool
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"},
},
# 需要的arguments
"required": [
"latitude", "longitude"
],
"additionalProperties": False
},
"strict": True
}
}]
这样我们就完成了一次Function Calling。给予了 LLM 更加强大的能力。
RAG(Retrieval-Augmented-Generation)#
紧跟着Tool Calling, LLM 拥有了获取外部信息的能力,那么很自然而然的,利用Tool Calling的思想和实际应用,我们是可以让 LLM 访问任何我们想要让访问到的内容的,这就是RAG场景(检索生成增强)。通过使用RAG,我们就可以构造一个独属于我们自己的知识库agent,或者是公司内部、工作室内部的agent。实现通过自然语言,就可以让 LLM 检索到我们需要的内容。这样的搜索被称为semantic search (语义化搜索)
Semantic Search#
实现语义化搜索,首先要了解到在 LLM 中,文本是如何存储的?简单来说,文本通过向量存储。大模型内部的世界我们无法想象,因为是高维的。** LLM 通过对比在他的“世界”中的文字(也就是向量),是否是语义相近的(两向量是否是挨在一起的),来找到和问题相关性强的文字,并进行输出。所以,要牢记的是文本通过向量存储**。自然而然地,如果我们想要让 LLM 在他的“世界”里,根据我们翻找提供给他的资料来进行回答问题,首先我们就需要把资料喂给他。一般分为以下步骤:
- Use Document Loader Load data
- Text Splitter
- Embedding
- Restore Data(Vector Store)
- Start Retrieval
Embedding#
Embedding,在RAG场景中是不可缺少的一环,也是最最重要的一环,通过这一步,文本才真正的被转化成了实际的数字向量,才能被 LLM 给检索到。一个Embedding就是一个向量(组),包含着一系列的浮点数数字,两个数字之间的距离代表着对应的文本直接的关联度,数字越小,对应的文本之间的关联度就越大,意思也就越相近。
目前各大AI厂商都有提供相对应的Embedding Model,通过使用Embedding Model将纯文本转换为数字向量。
准备数据#
首先,我们需要使用Document Loader,将对应的“文档”进行载入。这里使用 LangChain API进行示例:
from LangChain _community.document_loaders import PyPDFLoader
filepath = "../files/mapreduce.pdf"
loader = PyPDFLoader(filepath)
docs = loader.load()使用 LangChain 集成的各第三方插件载入数据,比如这里使用PyPDFLoader对PDF文件进行载入。
接着,开始text splitting,使用分词器,将载入的Document分割成合适的部分,让查询更加颗粒化:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# 设置add_start_index为true, 这样可以保留每个document的start_index 的属性
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
同时也不只是有这一种分词策略,按段分,按句子分等等…
为什么要使用分词器?:
Language Models are often limited by the amount of text that you can pass to them. Therefore, it is neccessary to split them up into smaller chunks. LangChain provides several utilities for doing so.
Using a Text Splitter can also help improve the results from vector store searches, as eg. smaller chunks may sometimes be more likely to match a query. Testing different chunk sizes (and chunk overlap) is a worthwhile exercise to tailor the results to your use case. 简单来说:将整个文本分割成合适的块(chunk)依次传递给 LLM 。因为 LLM 有着上下文窗口长度限制 然后,我们使用
Embedding Model向量化分词过后的数据(这里使用阿里百炼平台):
# 使用Embedding模型
from langchain_community.embeddings import DashScopeEmbeddings
import os
embeddings = DashScopeEmbeddings(dashscope_api_key=os.environ["DASHSCOPE_API_KEY"], model="text-embedding-v1")
vector_1 = embeddings.embed_query(all_splits[0].page_content)
vector_2 = embeddings.embed_query(all_splits[1].page_content) 得到了embeddings之后,我们将其存储在对应的向量数据库中(这里将其存储在内存中):
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
ids = vector_store.add_documents(documents=all_splits)
# 简单的语义搜索
# results = vector_store.similarity_search("What is the mapReduce concept?")
# 带有评判标准的语义搜索
results = vector_store.similarity_search_with_score("What is the mapReduce concept?")
doc, score = results[0]
print(doc)
print(score)
至此,整个文本的向量化就完成了!开发者可以通过原生API或者是LangChain等这样的开发框架,让 LLM 接入vector数据库。整个RAG场景就搭建结束了。
接下来#
接下来,目标就是给博客网站接入一个类似于Mendable ↗属于博客本身的AI。